

Challenges
Openfort enables users to manage wallets across multiple blockchain networks—a number that continues to grow. Managing JSON-RPC operations for this many chains requires a robust, unified infrastructure.
Our JSON-RPC management system needed to support:
- Multiple upstreams per chain with intelligent routing across RPC providers
- Dynamic optimization based on latency, cost, load, and rate limits
- ERC-4337 support for account abstraction
- Robust error handling with automatic retries and failover
- Local endpoint integration for in-house infrastructure
- High-performance async I/O for concurrent requests
- Smart caching to reduce costs and improve response times
- Horizontal scalability with stateless or coordinated instances
- Full observability with logs, traces, and metrics
Initial Solution
We built a Go-based solution leveraging its concurrency model and async I/O capabilities. The system used Redis for caching and Elasticsearch for upstream selection. It performed well and scaled horizontally, but as our user base grew, Elasticsearch began consuming excessive resources during high-load periods, creating CPU spikes that threatened other services.
We considered several approaches to address the Elasticsearch bottleneck:
- Query simplification – Reduce historical data evaluation at the cost of accuracy
- Performance optimization – Profile and tune Elasticsearch, requiring ongoing engineering effort
- CPU limiting – Cap Elasticsearch CPU usage, accepting increased latency
None of these solutions were ideal. We decided to explore alternatives that could eliminate our Elasticsearch dependency entirely.
Setup
Why eRPC?
eRPC emerged as a strong candidate, supporting all our existing requirements plus features we had planned to build. Key advantages included:
- Full feature parity with our in-house solution
- Open-source with permissive licensing and active community development
- Seamless integration with GKE and our monitoring stack
- Self-hosted deployment model
- Comprehensive documentation and responsive support channels
Additional features that enhanced our infrastructure:
- Hedging – Parallel requests to multiple endpoints for lowest latency
- Request batching – Intelligent RPC aggregation
- Integrity checks – Built-in validation for critical operations
Migration Process
We adopted a phased approach, starting with a single chain and a few upstreams to validate behavior. After confirming standard and ERC-4337 bundler calls worked correctly, we progressively added chains and upstreams until reaching feature parity with our in-house system.
During migration, we contributed upstream fixes for Pimlico providers and JSON-RPC encoding. We ran eRPC alongside our existing solution during a trial period, using this time to optimize configurations, tune upstream settings, and properly configure caching policies.
Deployment was straightforward thanks to eRPC's documentation and public Kubernetes configuration examples.
Key Challenge: Failsafe Upstreams
The eRPC team was responsive through community channels and GitHub. Our main challenge involved understanding failsafe upstream behavior.
We expected failsafe upstreams to be tried after all primary upstreams failed. For example, with upstreams A, B, and C (C marked as failsafe), we expected the sequence: try A → fails → try B → fails → try C. Instead, eRPC would give up after A and B without attempting C.
The issue: failsafe upstreams only activate when primary upstreams are marked "unhealthy," which requires multiple failures. During the threshold period, both A and B could fail without triggering the failsafe.
Solution: We configured failsafe upstreams as normal upstreams with a selection policy prioritizing low request counts. This ensures they're tried last when other upstreams are healthy, as higher usage decreases their priority.
Results
eRPC has significantly improved our infrastructure stability and scalability:
- Eliminated CPU spikes – Removed Elasticsearch bottleneck and resource contention
- Stable memory footprint – Predictable resource usage with clear scaling indicators
- Reduced latency – Most latency now from upstream providers, not our infrastructure
- Horizontal scalability – Consistent with our broader infrastructure principles
- Unified observability – Compatible logs and metrics across our stack
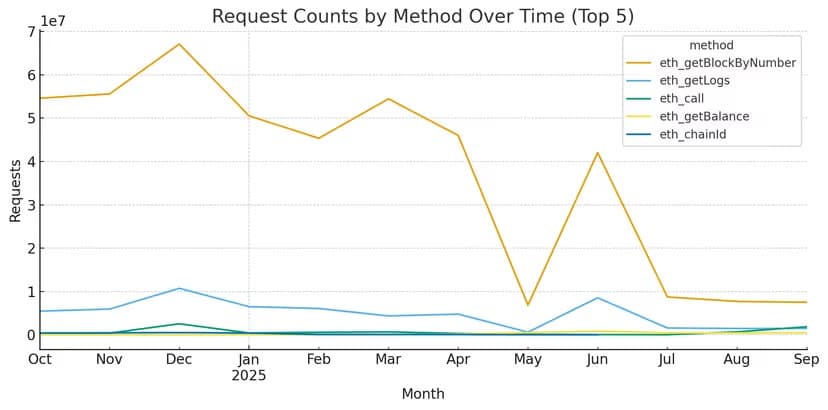
After deploying eRPC in June 2025, request volumes stabilized with:
- Elimination of traffic spikes and performance fluctuations
- Optimized request handling through buffer caching and RPC aggregation